ارزیابی و اعتبارسنجی روش های دسته بندی (Evaluation of classification performance) یک مرحله مهم و بسیار با اهمیت در ارزیابی روش دسته بندی و شاخصی برای رد یا قبول و موفقیت یا عدم موفقیت یک روش دسته بندی برای مجموعه داده مشخص است. عملکرد دسته بندی با مقادیر اسکالر عددی معیارهای مختلف مانند دقت، حساسیت و ویژگی نشان داده میشود. مقایسه روش های دسته بندی مختلف با استفاده از این معیارها آسان است، اما مشکلات زیادی مانند حساسیت به داده های نامتعادل (imbalanced data) و نادیده گرفتن عملکرد برخی از کلاس ها را نیز دارند.
روش ارزیابی یک عامل کلیدی در ارزیابی عملکرد دسته بندی و هدایت مدلسازی دسته بندی کننده است. سه مرحله اصلی فرآیند دسته بندی، یعنی مرحله آموزش، مرحله اعتبار سنجی و مرحله تست یا آزمایشی هستند. مدل با استفاده از الگوهای ورودی آموزش داده می شود و این مرحله فاز آموزش نامیده می شود. این الگوهای ورودی را داده های آموزشی می نامند که برای آموزش مدل استفاده می شود. در طول این مرحله، پارامترهای یک مدل دسته بندی تنظیم می شوند. خطای آموزش اندازه گیری می کند که مدل آموزش دیده چقدر با داده های آموزشی مطابقت دارد. با این حال، خطای آموزش همیشه کوچک تر از خطای تست و خطای اعتبار سنجی است، زیرا مدل آموزش دیده با همان داده هایی که در مرحله آموزش استفاده می شود، مطابقت دارد. هدف یک الگوریتم یادگیری (learning algorithm) ، یادگیری از دادههای آموزشی برای پیشبینی برچسبهای کلاس برای دادههای دیده نشده است که این در مرحله تست یا آزمون انجام می شود. در مرحله اعتبار سنجی، داده های اعتبار سنجی ارزیابی بی طرفانه ای از مدل آموزش دیده در حین تنظیم فراپارامترهای مدل ارائه می دهند.
بسیاری از پارامترهای آماری جهت ارزیابی و اعتبارسنجی روش های دسته بندی براساس ماتریس درهم ریختگی (confusion matrix) تعریف می شوند.
ماتریس در هم ریختگی
با توجه به تعداد کلاسها، دو نوع دسته بندی وجود دارد، یعنی دسته بندی باینری که فقط دو کلاس وجود دارد و دسته بندی چند کلاسه که تعداد کلاسها بیشتر از دو باشد. فرض کنید دو کلاس داریم، یعنی طبقه بندی باینری، P برای کلاس مثبت و N برای کلاس منفی. یک نمونه ناشناخته به P یا N طبقه بندی می شود. مدل طبقه بندی که در مرحله آموزش داده شده است برای پیش بینی کلاس های واقعی نمونه های ناشناخته استفاده می شود. این مدل طبقه بندی خروجی های پیوسته یا گسسته تولید می کند. خروجی گسسته ای که از یک مدل طبقه بندی تولید می شود، برچسب کلاس گسسته پیش بینی شده نمونه ناشناخته/تست را نشان می دهد، در حالی که خروجی پیوسته تخمین احتمال عضویت در کلاس نمونه را نشان می دهد.
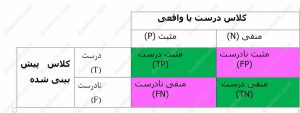
چندین پارامتر برای ارزیابی و تخمین کیفیت مدل های دسته بندی به کار می رود. برای همه روش های دسته بندی یک ماتریس در هم ریختگی (confusion matrix) تعریف می شود که یک ماتریس مربعی با ابعاد G×G است (G تعداد کلاس). شکل 1 نشان می دهد که چهار خروجی ممکن وجود دارد که عناصر یک ماتریس در هم ریختگی یا یک جدول احتمالی را نشان می دهد. رنگ سبز نشان دهنده پیش بینی های صحیح یا درست (True) و رنگ صورتی نشان دهنده پیش بینی های نادرست یا نادرست (False) است.
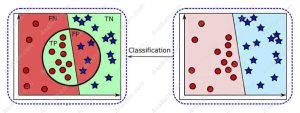
شکل1- مفاهیم مثبت درست (TP) مثبت نادرست (FP) منفی درست (TN) منفی نادرست (FN)
اگر نمونه مثبت (positive) باشد و به عنوان مثبت دسته بندی شود، یعنی به طور صحیح نمونه مثبت دسته بندی شده باشد، به عنوان مثبت واقعی یا مثبت درست (True positive) و با TP مشخص می شود. اگر این نمونه مثبت به عنوان منفی دسته بندی شود، به عنوان خطای منفی کاذب یا منفی نادرست (False negative) و با FN مشخص شود. حالتFN را خطای منفی کاذب یا خطای نوع II (Type II error) نیز می نامند. اگر نمونه منفی باشد و به عنوان منفی طبقه بندی شود به عنوان منفی واقعی یا منفی درست (True negative) و با TN مشخص می شود. اگر این نمونه منفی به عنوان مثبت دسته بندی شود، به عنوان مثبت کاذب یا مثبت نادرست (False positive) و با FP مشخص می شود. حالتFP را خطای مثبت کاذب یا خطای نوع I (Type I error) نیز می نامند. این پارامترها به خوبی در شکل 15 به ثصویر کشیده شده اند.
جدول 1 ماتریس در هم ریختگی را برای یک دسته بندی دوتایی (binary) را نشان می دهد. درک درست ماتریس در هم ریختگی بسیار مهم است چون برای محاسبه بسیاری پارامترهای ارزیابی روش های دسته بندی استفاده می شود.
جدول 1-ماتریس درهم ریختگی (confusion matrix) برای دسته بندی دوتایی یا باینری
پارامترهای ارزیابی و اعتبار سنجی روش های دسته بندی
صحت (Acc)
صحت (Accuracy) نسبت پیش بینی درست به تعداد کل نمونه هاست و طبق جدول 1 برای یک دسته بندی باینری به صورت زیر تعریف می شود:
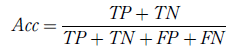 که در آن P و N به ترتیب تعداد نمونه های مثبت و منفی را نشان می دهد.
که در آن P و N به ترتیب تعداد نمونه های مثبت و منفی را نشان می دهد.
نرخ خطا (ERR)
نرخ خطا (Error Rate) با اختصار یا نرخ دسته بندی اشتباه (misclassification rate) مکمل پارامتر صحت دسته بندی ست.
ERR=1-Acc=(FP+FN)/(TP+TN+FP+FN)
این پارامتر تعداد نمونههای دسته بندی اشتباه مثبت و منفی را نشان میدهد.
حساسیت(Sn)، نرخ مثبت درست (TPR)، نرخ ضربه (hit rate)، یا یادآوری(recall)
حساسیت (sensitivity) یا نرخ مثبت درست (true positive rate) که با اسامی مختلفی بیان می شود معیاری ست از نمونه های دسته بندی شده به طور صحیح مثبت به تعداد کل نمونه های مثبت. و با رابطه زیر به دست می آید:
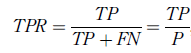
ویژگی (Sp)، نرخ منفی درست (TNR)، یا یادآوری معکوس (inverse recall)
ویژگی (specificity) یا نرخ منفی درست (True negative rate) که با اسامی مختلفی بیان می شود معیاری ست از نمونه های دسته بندی شده به طور صحیح منفی به تعداد کل نمونه های منفی. و با رابطه زیر به دست می آید:
![]()
بنابراین، ویژگی نشان دهنده نسبت نمونه های منفی است که به درستی دسته بندی شده اند، و حساسیت نسبت نمونه های مثبت است که به درستی دسته بندی شده اند. به طور کلی می توان حساسیت و ویژگی را دو نوع صحت (Acc) در نظر گرفت که اولی برای نمونه های مثبت واقعی و دومی برای نمونه های منفی واقعی به کار می روند. حساسیت به TP و FN بستگی دارد که در همان ستون ماتریس بهم ریختگی قرار دارند، و به طور مشابه، معیار ویژگی به TN و FP که در همان ستون هستند بستگی دارد. به زبان ساده حساسیت (Sn) مشخص کننده کارایی روش دسته بندی در پیش بینی درست نمونه های یک کلاس و ویژگی (Sp) نشان دهنده توانایی روش در پیش بینی درست کلاس دیگر است. به زبان ساده ویژگی نشان دهنده مثبت نادرست است و حساسیت مشخص کننده مثبت درست هستند. صحت کارایی روش دسته بندی برای پیش بینی همه دسته ها (کلاس ها) را نشان می دهد.
دقت (p) یا مقدار پیش بینی مثبت (PPV)
مقادیر پیش بینی کننده (مثبت و منفی) عملکرد پیش بینی را منعکس می کند. مقدار پیش بینی مثبت (Positive prediction value) یا دقت (precision) نشان دهنده نسبت نمونه های مثبت است که به درستی دسته بندی شده اند به تعداد کل نمونه های پیش بینی شده مثبت. که با معادله زیر به دست می آید:
![]()
به عبارت دیگر دقت، توانایی مدل دسته بندی در تشخیص درست نمونه های یک کلاس است.
برای آشنایی با پارامترهای دیگری چون شاخص یودن (Youden’s index) همبستگی متیوز (Matthews correlation coefficient) معیار فیشر (F-measure) منحنی راک (ROC) سطح زیر منحنی راک (Area under the ROC curve)و … به همراه مثال های کاربردی برای دسته بندی دوتایی و چند تایی به مقالات زیر رجوع کنید.
محاسبه پارامترهای ارزیابی و اعتبار سنجی روش های دسته بندی
اصول و مراحل روش ها ی دسته بندی