با افزایش توان فنی و پیشرفت های تکنولوژی، در چند دهه اخیر، شاهد رشد انفجاری تولید داده ها در حوزه های مختلف بوده ایم. این حجم عظیم از داده ها، نیازمند ابزارها و شیوه های مدرنی ست که در جمع آوری، ذخیره سازی و تبدیل داده های خام به اطلاعات و دانش به کار گرفته شوند. به نظر می رسد آشنایی با روش های دسته بندی یا روش های طبقه بندی و داده کاوی در بسیاری از زمینه های علمی، اجتماعی، اقتصادی و .. به درک بهتر ما از موضوع مورد نظرر کمک خواهد کرد.
روش های داده کاوی (data mining) به عنوان ابزاری توانمند در استخراج دانش و اطلاعات مفید از مقدار زیاد داده خام اولیه استفاده گسترده ای دارند. از عمده تکنیک هایی که برای داده کاوی در زمینه های مختلف به کار می رود عبارتند از: آمار کلاسیک، هوش مصنوعی و یادگیری ماشین. روش های داده کاوی برای آنالیز داده ها، و کشف الگوهای با ارزش و مفید از داده های اولیه به کار می روند. روش های خلاصه سازی، تشخیص الگو (pattern recognition)، دسته بندی (classification)، خوشه بندی (clustering) و تحلیل لینک (link analysis) از انواع روش های داده کاوی هستند.
دسته بندی کلاس بندی یا طبقه بندی (Classification) و خوشه بندی (Clustering) از شاخه های علوم داده (Data Science) هستند که به اشکال مختلف برای به دست آوردن الگو ها و کسب دانش در مورد الگوی حاکم بر انواع مختلف داده مورد استفاده قرار می گیرند. روش های دسته بندی از روش های بسیار مهم و کاربردی در بسیاری از علوم مانند شیمی، زیست شناسی، داروسازی و پزشکی، جامعه شناسی، اقتصاد، بازاریابی و .. هستند. در فرآیند داده کاوی، ابتدا مجموعه بزرگی از داده های پردازش می شوند، سپس الگوهای بین داده ها شناسایی شده و روابط و تکنیک هایی برای انجام تجزیه و تحلیل داده ها و حل مسائل استفاده می شود. و در نهایت از این الگو ها برای پیش بینی استفاده می شود. پس به طور خلاصه دسته بندی یا طبقه بندی یک کار علمی بر روی داده هاست که برای پیش بینی مقدار متغیر طبقه بندی شده (هدف یا کلاس) با ساختن یک مدل بر اساس یک یا چند متغیر عددی و / یا دسته ای (پیش بینی کننده یا ویژگی) به کار می رود.
هدف روش های دسته بندی یافتن مدل هایی ست که قادر باشند عضویت (membership) هر شی را بر اساس مجموعه ای از اندازه گیری ها به کلاس مناسب خود مرتبط کند. روش های رگرسیون پاسخ های کمی را بر اساس پارامترهای کمی مدل می کنند اما روش های دسته بندی پاسخ های کیفی را مدل می کند. به عبارت دیگر هدف روش های دسته بندی پیدا کردن یک رابطه ریاضی بین متغیرهای توصیفی (descriptive variable) و پاسخ (qualitative response) کمی ست. برای آشنایی با روش های دسته بندی چند اصطلاح و واژه مهم و کاربردی را در ادامه تعریف می کنیم.
دسته بندی و خوشه بندی
خوشه بندی (clustering) یک روش تشخیص الگو بدون نظارت (unsupervised learning) است. در روش های خوشه بندی هیچ دسته ای از قبل وجود ندارد و هدف اصلی پیدا کردن زیر گروه هایی است که با هم شباهت دارند و یا به عبارت ساده تر با توجه به میزان نزدیکی یا شباهت بین اعضا آنها را در یک گروه قرار می گیرند. در واقع اصل اولیه روش های خوشه بندی تقسیم بندی داده های اولیه به نحوی که داده های موجود در یک گروه بسیار به هم شبیه باشند و داده های موجود در یک گروه های مختلف بسیار حداکثر تفاوت ممکن را نسبت به هم داشته باشند.
به روش های دسته بندی (classification) روش تشخیص الگو با نظارت (supervised pattern recognition) نیز گفته می شود. روش های دسته بندی کاربرد روزافزون و گسترده ای در زمینه های مختلف مانند شیمی داروسازی فارماکولوژی صنایع غذایی اقتصاد و علوم اجتماعی دارند.
مشابه دیگر روش های آماری و همین طور براساس ورودی اکثر نرم افزارها مرسوم و متداول نظیر MATLAB, R, Unscrambler, در این روش ها نیز باید ماتریس داده را برای هدف مورد نظر تعریف کرد. برای n شی (object) با p متغیر توصیفی یک ماتریس داده (X) با ابعاد n×p باید ایجاد شود که هر درایه آن (Xij) نشان دهنده مقدار پارامتر توصیفی(j) برای شی موردنظر (i) باشد. پاسخ (G) شامل برچسب (label) یا دسته بندی هر شی است که می تواند یک بردار یا ماتریس باشد . سپس از روش های خطی یا غیرخطی برای ساختن مرزهای (boundary) دسته بندی بین ماتریس X و بردار پاسخ استفاده می شود.
انواع دسته بندی
بر اساس تعداد دسته یا کلاس هایی که باید مدل شده و پیش بینی شوند دسته بندی به دو روش کلی زیر تقسیم می شوند: دسته بندی دوتایی یا باینری و دسته بندی چند کلاسی.
دسته بندی دوتایی یا باینری
دسته بندی دوتایی یا باینری (Binary Classification) مربوط به دسته بندی دوتایی ست و مسائلی که به صورت صفر و یک، آری یا نه، بیمار و سالم، خوش خیم یا بدخیم، و .. مطرح می شوند، را شامل می شود. از نظر محاسباتی و تجزیه و تحلیل بسیار آسان تر و قابل فهم تر از دسته بندی چند کلاسی هستند. شکل 1- دسته بندی دوتایی یا باینری را به صورت تصویری نشان می دهد.
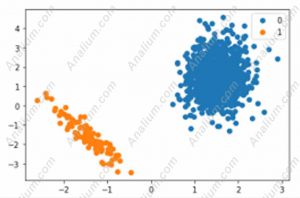
شکل 1- دسته بندی چند کلاسی
دسته بندی چند کلاسی
دسته بندی چند کلاسی (Multi-Class Classification) برای دسته بندی داده های با بیش از دو کلاس به کار می روند. به طور مثال، در شکل زیر داده ها در 3 کلاس متفاوت قرار دارند. مانند طبقه بندی چهره، طبقه بندی گونه های گیاهی و حیوانی و غیره که به کلاس های متفاوتی (بیش از 2 کلاس) تقسیم می شوند در دسته مسائل طبقه بندی چند کلاسی قرار می گیرد.
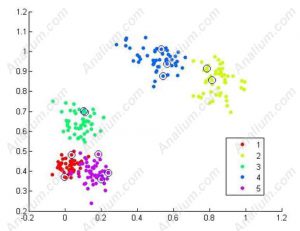 شکل 2- دسته بندی چند کلاسی
شکل 2- دسته بندی چند کلاسی
دسته بندی خطی و غیر خطی
بر اساس نوع مرز بندی (boundary) برای جداسازی دسته ها از هم روش های دسته بندی به دو نوع خطی (linear boundary) و غیرخطی (non-linear boundary) تقسیم می شوند. در روش های خطی مرز بندی بین کلاس های مختلف به صورت خطی صورت می گیرد اما در روش های غیر خطی مرزبندی ها غیر خطی هستند. همان طور که از شکل 3 مشخص است مرزبندی بین کلاس ها با روش های خطی نمی تواند به طور کامل انجام شود (فضای خاکستری که در مرزبندی کلاس ها قرار نمی گیرند). بنابراین روش های غیر خطی عموما کارایی بهتری در دسته بندی خصوصا در انواع چند کلاسه دارند.
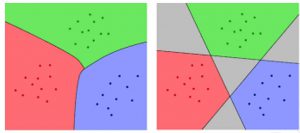
شکل 3- دسته بندی خطی و غیر خطی
روش های دسته بندی بر حسب الگوریتم های یادگیری نیز به دو دسته کلی یادگیری نظارت شده و یادگیری نظارت نشده تقسیم می شوند.
یادگیری نظارت شده
در یادگیری نظارت شده (Supervised Learning) یا یادگیری با ناظر داده های آموزشی (مشاهدات، اندازه گیری ها و غیره) با برچسب هایی همراه است که طبقه یا کلاس مشاهدات را نشان می دهد و داده های جدید بر اساس مدل ساخته شده بر روی مجموعه آموزش طبقه بندی می شوند. در الگوریتم ها ی نظارت شده با دو نوع متغیر سروکار داریم. متغیرهای مستقل و متغیر وابسته. متغیرهای مستقل، متغیرهایی هستند بر اساس مقادیر آنها، یک متغیر دیگر مدل سازی و پیش بینی می شود. مثلا شدت های یک طیف برای تعیین غلظت یک نمونه، یا سن، تحصیلات درآمد، و وضعیت تاهل برای پیش بینی خرید یک کالا توسط یک مشتری، متغیرهای مستقل هستند. متغیرهای وابسته یا هدف متغیر نهایی ست که مقادیر آنها به کمک این الگوریتم های یادگیری و براساس مقادیر متغیرهای مستقل پیش بینی می شود . برای این منظور باید تابعی ایجاد کنیم که ورودی ها یا متغیرهای مستقل را گرفته و خروجی موردنظر یا همان متغیر وابسته یا هدف را مدل سازی کند. فرآیند یافتن این تابع که در حقیقت کشف رابطه ای بین متغیرهای مستقل و متغیرهای وابسته است را فرآیند آموزش (Training Process) نامیده می شود. الگوریتم آموخته شده برای پیش بینی داده های جدید به کار می رود.
یادگیری نظارت نشده
در الگوریتم های یادگیری نظارت نشده (unsupervised learning) یا یادگیری بدون ناظر متغیر هدف وجود ندارد و خروجی الگوریتم، نامشخص است. در واقع در این نوع یادگیری برچسب کلاس داده های آموزشی ناشناخته است. بهترین مثالی که برای این نوع از الگوریتم ها می توان زد، گروه بندی خودکار (خوشه بندی) یک جمعیت است مثلاً با داشتن اطلاعات شخصی و خریدهای مشتریان، به صورت خودکار آنها را به گروه های همسان و هم ارز تقسیم کنیم.
یادگیری نیمه نظارت شده (semi-supervised Learning) نیز نوعی از یادگیری است که هم از داده های طبقه بندی شده (برچسب خورده) و هم از داده های غیر طبقه بندی شده (برچسب نخورده) به صورت همزمان استفاده می شود تا دقت یادگیری مقداری بهبود یابد.
معرفی نرم افزار های دسته بندی
با توجه به گستردگی روزافزون استفاده از روش های دسته بندی و تشخیص الگو در رشته های مختلف تحقیقاتی و صنعتی، نرم افزارهای تجاری و رایگان بسیاری روانه بازار شده و در دسترس هستند.
در استفاده از نرم افزارهای متن باز (open source) یا رایگان، باید دقت لازم به عمل آید. بعضی از نرم افزارهای رایگان با الگوریتم های محاسباتی ضعیف و یا اشتباه، قدرت محاسبات کمتر، عدم نمایش گرافیکی نتایج و یا محدودیت در تعداد ورودی همراه هستند. اگرچه تعداد نرم افزارهای شناخته شده رایگان و مورد اعتماد نیز ارائه شده اند. جدول 1 تعدادی از برنامه های و نرم افزارهای متداول و قابل دسترس با کاربری مناسب به همراه آدرس وب سایت برای انواع روش های دسته بندی و خوشه بندی را فهرست کرده است.
جدول 1 – برنامه های و نرم افزارهای متداول برای انواع روش های دسته بندی
| وب سایت | نام |
|---|---|
| https://www.r-project.org/ | R statistical package |
| https://www.mathworks.com/products/matlab.html | Matlab |
| https://www.cs.waikato.ac.nz/ml/weka | Weka |
| https://rapidminer.com | Rapid Miner |
| https://www.ibm.com/products/spss-statistics | SPSS |
| https://www.python.org | Python |
| https://www.sas.com/en_us/software/enterprise-miner.html | SAS Data Mining |
برای آشنایی بیشتر مباحث روش های دسته بندی مقالات زیر توصیه می شوند: