در مقاله قبل بر لزوم آشنایی با روش های دسته بندی به ویژه در زمینه هایی که با تولید داده همراه است مانند روش های طیف سنجی تاکید شد. در ادامه سعی خواهیم کرد تا با بیانی ساده اصول و مراحل روش های دسته بندی را شرح دهیم.
هدف روش های دسته بندی، پیش بینی پاسخ کیفی است، که تعلق به یک دسته خاص (y = 1، 2، 3،…، G؛ G که تعداد کل کلاس ها است) نمونههای آنالیز شده بر اساس دادههای اندازهگیری شده را کدگذاری میکند. به عنوان مثال اگر مشکل طبقهبندی شامل احراز هویت نمونههای ماهی باشد، دسته « ماهی قزل آلا» را میتوان به مقدار y=1، « ماهی سفید» به y=2 و « ماهی کپور» به y=3 مرتبط کرده و کلاس بندی کرد. متغیرهای اندازه گیری شده از این ماهی ها (به عنوان مثال پروفایل اسدهای آمینه) به عنوان متغیرهای مستقل برای دسته بندی ماهی ها به کار می روند. برخلاف روش های خوشه بندی روش های دسته بندی از نوع نظارت شده هستند. یعنی به مجموعهای از نمونهها نیاز دارند که کلاس آنها مشخص باشد (مجموعه آموزش) زیرا این اطلاعات به طور فعال برای ساخت مدل استفاده می شود.
مراحل روش های دسته بندی
- جمع آوری داده اولیه و آماده سازی داده ها
- انتخاب ویژگی های مناسب و پیش پردازش
- مدل سازی با انواع روش های دسته بندی یا دسته بندی کننده ها (classifier)
- ارزیابی مدل دسته بندی کننده (model evaluation)
- استفاده از مدل پیشنهادی برای پیش بینی نمونه ها یا داده های ناشناخته
شکل 1 مراحل کلی فرایند دسته بندی را نشان می دهد.
داده های اولیه باید با دقت جمع آوری شوند. سوالات خود را مشخص کنید. هدف از انجام دسته بندی را معین کنید. و شروع به کاوش در داده های مربوط به سوالات خود کنید. متغیر وابسته را به درستی انتخاب کنید و برچسب گذاری نمونه ها را با دقت انجام دهید. تصمیم گیری دقیق متغیر وابسته و تعداد کلاس ها برای متغیر وابسته می تواند حیاتی ترین انتخاب یک روش طبقه بندی باشد. این تصمیم معمولاً به دانش زمینه ای بستگی دارد و باید چندین بار در طول یک پروژه تجزیه و تحلیل داده ها مورد بازبینی قرار گیرد. به یاد داشته باشید شما بهترین شخصی هستید که با توجه به آگاهی از داده های اولیه و هدفی که دارید می توانید بهترین مسیر را برای یک روش دسته بندی موفق انتخاب کنید. توجه کنید که بدون داده های با کیفیت هیچگاه دسته بندی درست و موفقی نخواهیم داشت و کیفیت نتایج دسته بندی به کیفیت داده های اولیه به شدت وابسته است.
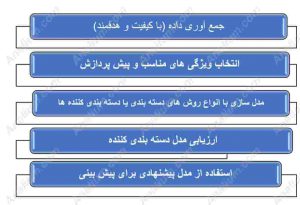
شکل 1 –مراحل کلی فرایند دسته بندی
برای هر مجموعه داده، اولین کاری که می خواهید انجام دهید این است که مجموعه داده خود را تمیز کرده (Data cleaning) و تجزیه و تحلیل داده های اکتشافی انجام دهید.
ویژگی (Feature) یک خاصیت قابل اندازه گیری و خاص از یک پدیده قابل مشاهده است. یک متغیر وابسته می تواند با تعداد محدود و یا بسیار زیادی از ویژگی های منحصر به فرد تعریف شود. انتخاب ویژگی (feature selection) فرآیند کاهش تعداد متغیرهای ورودی هنگام توسعه یک مدل پیش بینی است. کاهش تعداد متغیرهای ورودی برای کاهش هزینه محاسباتی مدل سازی و در برخی موارد برای بهبود عملکرد مدل بسیار مطلوب است. روشهای انتخاب ویژگی مبتنی بر آمار شامل ارزیابی رابطه بین هر متغیر ورودی و متغیر هدف با استفاده از آمار و انتخاب آن دسته از متغیرهای ورودی است که قویترین رابطه را با متغیر هدف دارند. این روش ها می توانند سریع و موثر باشند، اگرچه انتخاب معیارهای آماری به نوع داده متغیرهای ورودی و خروجی بستگی دارد. انتخاب ویژگی به ویژه در مجموعه داده هایی با متغیرها و ویژگی های زیاد بسیار با اهمیت است چون متغیرهای بی اهمیت را حذف می کند و دقت و همچنین عملکرد طبقه بندی را بهبود می بخشد.
روش های انتخاب ویژگی نیز به دو دسته کلی نظارت شده (supervised) و نظارت نشده (Unsupervised) تقسیم می شوند.
پیش پردازش داده ها
پیش پردازش (pre-processing) داده ها فرآیند تبدیل داده های خام به یک قالب قابل درک است. همچنین یک مرحله مهم در داده کاوی است زیرا ما نمی توانیم با داده های خام کار کنیم. قبل از اعمال الگوریتم های یادگیری ماشین یا داده کاوی، کیفیت داده ها باید بررسی شود. تبدیل داده (data transformation) تغییری که در قالب یا ساختار داده ایجاد می شود، یکی از روش های رایج پیش پردازش داده ها برای روش های طبقه بندی هستند. تبدیل داده می تواند بر اساس الزامات ساده یا پیچیده باشد. معمول ترین روش های تبدیل داده عبارتند از: هموارسازی (smoothing) تجمیع (Aggregation) گسسته سازی (Discretization) نرمال کردن (Normalization) از روش های متداول در روش های دسته بندی به شمار می روند. برای آشنایی بیشتر با این روش ها مقاله زیر را بخوانید.
اصول و مراحل روش ها ی دسته بندی
در روش های طبقه بندی با نظارت از یک مجموعه آموزشی (training) یا کالیبراسیون (calibration) جهت ساخت مدل استفاده می شود. این مجموعه آموزشی بر اساس روش های دسته بندی کننده (Classifier) مدل می شوند و سیستم مدل سازی آموزش می بیند تا داده ها را به گروه های درست با کمترین خطا دسته بندی کند. مجموعه ی آموزش حاوی داده هایی است که دسته ی آنها مشخص است. هر الگو یا دسته یک برچسب (Label) دارد و داده هایی با برچسب هدف یکسان در یک گروه قرار می گیرند. مجموعه آزمون یا آزمایش (Test) و یا مجموعه پیش بینی (Prediction) شامل اعضایی ست که برچسب آنها مشخص نیست. برای اعتبار سنجی روش دسته بندی معمولا حدود 80% از داده های موجود در دیتاست را به عنوان داده آموزش انتخاب کرده و 20% داده های باقی مانده را برای آزمون و اعتبارسنجی انتخاب می کنیم. در فاز تست داده هایی که برچسب آنها مشخص نیست به سیستم داده می شوند و سیستم طراحی شده به کمک تابع یادگرفته شده خروجی یا برچسب یا کلاس آنها را پیش بینی می کند.
ارزیابی و اعتبارسنجی روش های دسته بندی (Evaluation of classification performance) یک مرحله مهم و بسیار با اهمیت در ارزیابی روش دسته بندی و شاخصی برای رد یا قبول و موفقیت یا عدم موفقیت یک روش دسته بندی برای مجموعه داده مشخص است. انواع پارامترهای برای ارزیابی روش دسته بندی در مقاله زیر به خوبی شرح داده شده اند.
ارزیابی و اعتبار سنجی روش های دسته بندی
مرحله آخراستفاده از مدل پیشنهادی برای پیش بینی نمونه ها یا داده های ناشناخته است. در واقع در این مرحله از مدل دسته بندی برای نمونه های واقعی استفاده می شود و کارایی و موفقیت روش دسته بندی در این مرحله نهایی می شود.
برای آشنایی بیشتر با مباحث مرتبط با روش های دسته بندی مقالات زیر را ببینید: